在开始之前,必须指出 RAFT 不是具体的分布式系统设施,比如 GFS 和 VM-FT 就是提供具体功能的分布式设施。RAFT 是一种算法,它可以应用在具体的分布式系统中以维护容错性并保持一致性。
同时,RAFT 是为了容错构建。在 RAFT 中读取请求也需要由领导者处理,领导者确定自身无误后将自身日志中的数据返回给客户端,其他跟随者节点并不直接处理读取请求。这与 GFS 为并发性构建的分布式系统不同,RAFT 的副本是为容错设计的。
共识算法概述

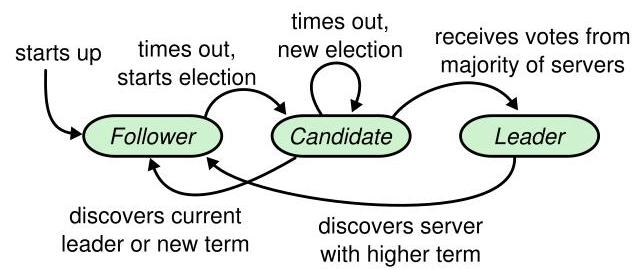
领导者选举
何时选举:
当某个跟随者节点,长时间未收到领导者的心跳包,触发超时机制成为候选者。候选者将当前任期+1 并向其他节点拉票(自己先投自己一票),如果获得大多数节点的投票即成功晋身领导者。节点只有一票,将投给第一个满足条件的候选者。
但以上描述过于模糊,我们需要进一步解决以下问题:
- 候选者的任期如何计算?
- 节点如何决定投票给谁?
- 如何得知自己是多数选票获得者?
- 如果有多个候选者并列第一,如何处理?
- 如果一次选举成功了,整个集群的节点是如何知道的呢?
候选者的任期如何计算?
每个节点本地维护一个 currentTerm(当前任期)变量,任何时刻,只要节点看到一个更高的 term,就更新自己的 currentTerm;在发起选举时,节点会将其 currentTerm + 1,并广播自己的新 term。
不要认为任期是全局递增的。每个节点的 currentTerm 是本地维护的,只有在收到更高 term 的 RPC 时才会更新。
节点如何决定投票给谁?
RAFT determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date. RAFT 通过比较日志中最后一个条目的索引和任期来判断两个日志哪个更新。如果日志的最后一个条目任期不同,则任期较晚的日志更新。如果日志结尾的任期相同,则较长的日志更新。
有两个部分将决定这件事:候选者的任期、候选者的 log 索引是否足够新。二者的优先级是任期>索引
候选者的任期:如果候选者的任期大于自己的任期,就投票给它。反之,对方任期小于自己时不投票。但二者的任期一致,使用 log 索引进行判断。
候选者的 log 索引是否足够新:当两者任期相等时,日志索引较新的一方获胜。
如何得知自己是多数选票获得者?
在集群启动时会配置节点数量,候选者根据配置可以判断自己是否获得超过半数的选票。这可以有效避免集群因网络故障,形成两个无法沟通的子集群,进而产生脑裂问题。
如果有多个候选者并列第一,如何处理?比如两个候选者各自获得了一半的选票
选举存在超时机制,当限定时间内没有任何节点获得超过半数的选票,该任期作废。注意,每次选举失败后,候选者会递增自己的任期(term)并重新发起选举。 也就是说,任期会继续递增,某节点任期 4 选举时集群没有产生新的节点,重新选举时任期会变为 5。同时,RAFT 通过随机化的选举超时机制来减少并列第一的可能性。每个候选者会随机选择一个选举超时时间(如 150-300 毫秒),同时每次触发后需要再次重新随机选择,这有助于避免多个候选者在同一时间再次竞争选票。
如果一次选举成功了,整个集群的节点是如何知道的呢?
首先,候选者发现自己获得了过半选票,立刻认为自己成为领导者。而其他节点无需知晓具体的领导者节点 ID,因为候选者成功竞选后会立刻发送心跳,只有领导者才会发送心跳,心跳包含任期信息,由此其余节点就会得知新的任期出现了并且领导者也出现了。
日志
日志(log)是领导者控制操作排序的手段,副本按顺序执行日志以保证状态相同并且顺序相同。类似两阶段提交,RAFT 中的跟随者接到日志后返回确认,等待领导者通知日志已实际提交,再实际执行或持久化日志。所以,对于 RAFT 的跟随者来说,Log 是用来存放临时操作的地方。同时,log 也帮助节点从崩溃中恢复,节点重新启动时会读取 log,但实际执行依旧需要领导者进行控制,后文会进行讨论。
在 Mit6.824 上,学生提出了和 VM-FT 类似的问题:如果跟随者落后领导者太多了,这是否会影响整个系统。毫无疑问,如果大多数跟随者均运行的比领导者慢太多,整个系统缺失会缓慢下来。因此,Robert 教授认为,实际系统应该会提供额外的消息来调节领导者的速度。
日志复制
RAFT 通过以下方式确保领导者和跟随者的日志相同:
- 领导者会将客户端请求产生的日志广播到所有跟随者,同时永久重试直到跟随者进行响应。
- 日志条目除了日志内容本身,还包含两个信息:日志的全局索引序号、该日志的任期号。
- 领导者在多数跟随者响应完成后(过半票决),提交该日志以持久化。注意,这时该日志之前的日志也被持久化。
- 如何判断日志是否匹配:两个日志条目具有相同索引和任期即匹配、两个匹配的日志条目之前的所有日志均匹配。
- 领导者发送的日志条目同时包含紧跟的前一条日志条目。
- 跟随者验证前一条日志条目是否已经收到并匹配,否则拒绝该新日志内容。这将递归的保证日志条目匹配。
日志匹配属性包括:
- 如果两个日志在相同索引处的日志条目具有相同的任期号和命令,则这两个日志在此索引前完全一致;
- 如果两个日志在某索引处有不同条目,则它们在该索引之后的所有条目也一定不同。
由此,每当 AppendEntries 成功返回时,领导者就知道跟随者的日志与其自身日志在新条目处完全一致。
值得一提的是,对于读取请求,领导者也会先向跟随者发送心跳,直到多数跟随者返回确认(包括领导者自己),确认自身依旧为领导者后才会返回读取请求。
在论文中,明确指出领导者只会维护自己任期的commitIndex。
To eliminate problems like the one in Figure 8, RAFT never commits log entries from previous terms by counting replicas. Only log entries from the leader's current term are committed by counting replicas
准确来说,领导者依旧会复制以前任期留下的日志(可能是上一个 Leader 的)。但领导者不会尝试提交其他任期的日志,而是通过跟随者的“某个日志已提交,则之前的日志均已提交”让跟随者自行提交其他任期的数据。
日志的不一致
注意,论文特意说明任期可能不连续:
A follower may be missing entries that are present on the leader, it may have extra entries that are not present on the leader, or both. Missing and extraneous entries in a log may span multiple terms. 一个跟随者可能缺少领导者日志中存在的条目,也可能包含领导者日志中不存在的额外条目,或者两者兼有。日志中缺失和多余的条目可能跨越多个任期(term)。
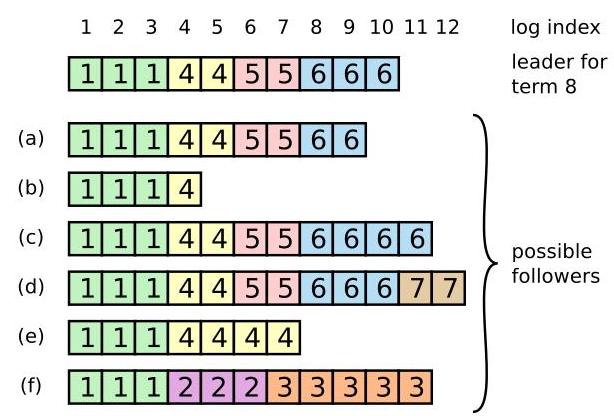
有许多原因会导致任期不连续:
- 重新选举时任期再次+1,后续写入的日志会直接跳过中间的任期。
- 某个节点完整的错过了多个任期,再次上线后更新了本地任期,这样日志也会产生不连续。
同时,如果某个节点虽然任期更大,日志也较新,但它并未参与选举(比如它自己是旧领导者,同时与多数节点失联),而其他过半的节点投票给了候选者。那么,这个新的领导者的数据将小于该未参与选举的节点,但新领导者将会强制覆盖日志,最后系统将保持一致。
为了使跟随者的日志与自身一致,领导者必须找到两个日志一致的最新条目,删除跟随者日志中该点之后的所有条目,并将领导者日志中该点之后的所有条目发送给跟随者。所有这些操作都发生在 AppendEntries RPC 执行的一致性检查响应中。领导者为每个跟随者维护一个 nextIndex 值,即领导者将发送给该跟随者的下一个日志条目的索引。当领导者首次上任时,它会将所有 nextIndex 值初始化为自身$\log$之后的索引。如果跟随者的日志与领导者不一致,则下一次 AppendEntries RPC 的一致性检查将失败。拒绝后,领导者递减 nextIndex 并重试 AppendEntries RPC。最终,nextIndex 将到达领导者和跟随者日志匹配的位置。此时,AppendEntries 将成功,从而清除跟随者日志中任何冲突的条目,并追加来自领导者日志的条目(如果有的话)。一旦 AppendEntries 成功,跟随者的日志便与领导者一致,并将在整个任期中保持一致。
同时,领导者不会删除或覆盖自己的条目(领导者只追加特性),由此集群会在运行中逐渐收敛。
时间与可用性
除了选举阶段,RAFT 尽可能不依赖时间保证安全性。为此,RAFT 对时间的要求仅需:广播时间 << 选举超时 << MTBF。
广播时间是指服务器向集群中每个服务器并行发送 RPC 并接收它们响应的平均时间。
选举超时是用于控制跟随者(follower)在未收到领导者(leader)心跳消息时,开始选举新领导者的等待时间,注意正如前文所述,这个时间是在一定范围内随机设定,以此尽量避免多个候选者获得相同的选票的情况。
MTBF 是单个服务器的平均故障间隔时间。
广播时间应比选举超时小一个数量级,这样领导者可以可靠地发送心跳消息以防止 follower 开始选举;考虑到选举超时采用随机化方法,这一不等式也能使分裂选票的可能性降低。选举超时应比 MTBF 小几个数量级,以确保系统能稳步前进。领导者崩溃时,系统将不可用大约等于选举超时的时间;我们希望这仅占总时间的一小部分。
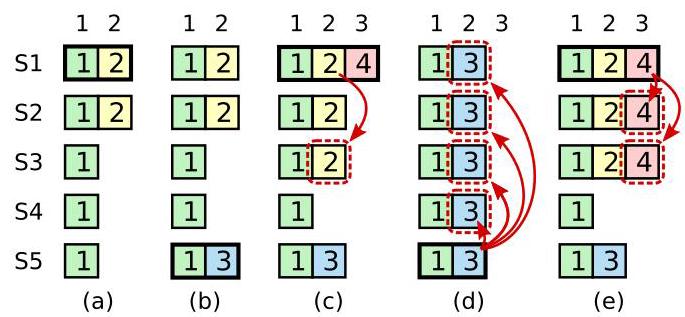
论文中的图-8困扰了我很久。我阅读的时候一直认为 图8 描述了合格的RAFT会出现的情况,那么自然会引出一个困惑:在情况 (c) 下,如果S1是在 (index=2,term=2) 提交后才崩溃的,按照选举时日志比较规则:最后一条日志,任期较新则认为日志较新。S5作为用于 term=3 的节点,是集群中最新的日志,完全可能成为新的领导者。而 RAFT 又明确说明领导者日志只追加且集群最终会收敛到领导者的日志。那重点是 RAFT 是一个强一致性算法,居然会丢失已经提交的日志?不可思议!
我半天才想明白,图-8在一个合格的 RAFT 实现中不会出现!特别是 (c) 情况,S5 不可能在缺失(index=2,term=2)的情况下获得 term=3 的日志。我们思考 term=3 的日志会如何产生:一定有一个 term=3 的节点当选了,才能在日志中追加 term=3 的条目。在 (index=2,term=2) 已经提交的情况下,大多数节点不会投票给一个缺失了 (index=2,term=2) 的节点,因此能够产生 term=3 的节点,必然拥有 (index=2,term=2) 。
因此,RAFT 后续的重点在描述如何避免图-8的情况。
Q&A
Q:当 follower 接受 AppendEntries 日志时,follower 如何检查日志?冲突时如何 follower 和 leader 分别如何处理?
A:Follower 在接收 AppendEntries 时,会用 prevLogIndex 和 prevLogTerm 检查前一条日志是否匹配。如果索引不存在或 term 不一致,Follower 返回 false;如果匹配,Follower 会删除该索引之后的所有冲突日志,并追加新日志。Leader 收到 false 后,会递减该 Follower 的 nextIndex 并重试,直到找到一致的前缀位置,再从该位置追加剩余日志。
Q:当 follower 接到一条提交(commit)通知时,follower 会做什么?
A:首先,follower 本地维护了自己的 commitIndex,记录了自己提交的日志序号。接下来,当接到新的 AppendEntries RPC 且通过一致性检查后时,follower将进行以下更新commitIndex=min(leaderCommitIndex, index of last new entry)。接着,follower 会认为 commitIndex 之前的所有日志均已提交。
Q:RAFT 如何避免旧AppendEntries到达时,follower回退的问题?
A:假设有一个旧AppendEntries在网络中被延迟了很久,follower已经应用了新的日志并且向后推进了状态。此时,旧AppendEntries才到达follower,follower会进行正常的检查:
|
|
Q:当一个旧leader节点仍然认为自己是leader时会发生什么? A:一个旧leader发送的AppendEntries必定会因为term过期而拒绝,此时返回的数据中包含了follower自己的term,旧leader检查follower's term将发现自己已过期。旧leader立即停止发送 AppendEntries并转为follower。
总结
为了构建能够自动恢复,同时避免脑裂的分布式系统,过半票决(Majority Vote)是非常关键的一点:在任何时候为了完成任何操作,你必须凑够过半的服务器来批准相应的操作。这一点在 RAFT 中广泛体现,从日常运行的事务提交到新领导者的产生。
为了实现过半票决,集群的总节点数应该是奇数,这样即使集群被彻底分裂为两部分,依旧有一部分能凑够超过半数的投票,从而继续提供服务。
参考资料
- Students' Guide to RAFT
- In Search of an Understandable Consensus Algorithm (Extended Version)